


The Evolution of Web Application Deployment: From Servers to the Edge

Remember debugging Apache mod_rewrite rules at 3 AM?
Picture this scenario that haunted developers for years: an app works perfectly on localhost, but the moment it hits the production server, everything breaks. The PHP version is different. File permissions are wrong. That MySQL query runs fine locally but throws character encoding errors in production. Sound familiar?
Those were the days when "deployment" meant FTPing files to a server and crossing your fingers. If you were lucky, you had SSH access. If not, you were stuck with cPanel and a lot of hope. Environment setup meant manually installing dependencies, configuring web servers, and praying that your hosting provider's setup matched your development machine.
The "it works on my machine" meme exists for a reason.
Fast forward to today. Developers push code to GitHub and watch it automatically deploy to edge locations across six continents. No Apache configurations. No PHP version mismatches. No late-night server crashes. Just code → global deployment in under a minute.
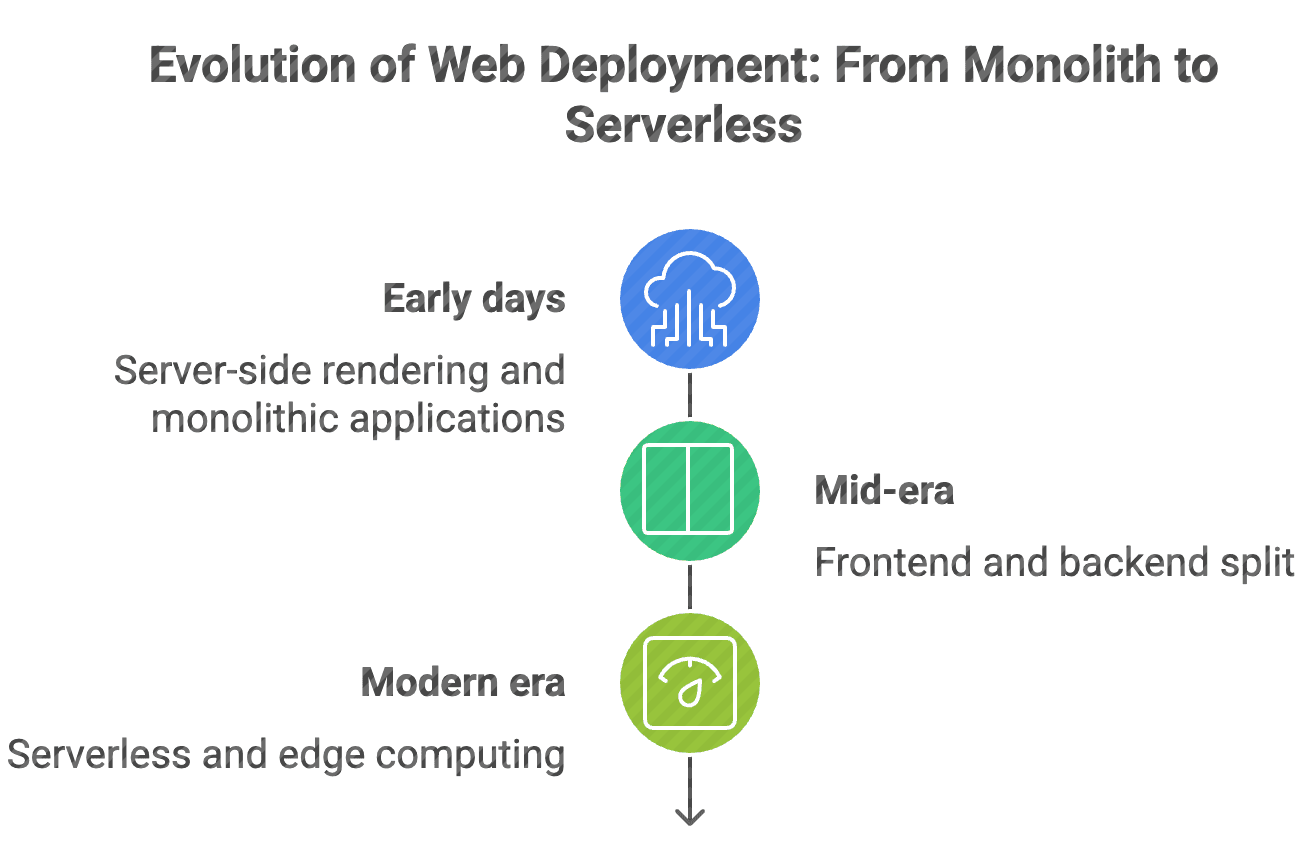
The contrast is striking, but this transformation didn't happen in one leap. Web deployment evolved through three distinct phases, each solving the biggest pain points of its time while creating new possibilities.
Phase one started with server-side rendering and monolithic applications. Everything lived on one machine, and deployment meant manually configuring that machine to perfection. Then came the great separation—frontend and backend split apart, introducing new complexities but enabling better user experiences.
Today's serverless and edge computing represents the latest evolution. Code deploys globally without thinking about servers at all. The infrastructure just... works.
Understanding this evolution helps explain why modern deployment platforms work the way they do—and where things might be heading next.
Phase 1: The Server-Side Rendering Era
When Servers Did Everything
In the beginning, there was the server. And the server was responsible for... well, everything.
Your web application lived entirely on one machine (or a few machines if you were fancy). The server received requests, queried the database, processed business logic, generated HTML, and sent complete web pages back to browsers. Every click meant a full page reload.
This was the world of LAMP stacks (Linux, Apache, MySQL, PHP), Windows servers running ASP, and Java applications deployed to Tomcat.
<?php
// This was cutting-edge dynamic content
include 'config.php';
$db = mysql_connect($host, $user, $pass);
$user_id = $_SESSION['user_id'];
$query = "SELECT * FROM users WHERE id = $user_id";
$result = mysql_query($query);
$user = mysql_fetch_array($result);
echo "<h1>Welcome back, " . $user['name'] . "!</h1>";
echo "<p>You have " . count_user_messages($user_id) . " new messages.</p>";
?>The Deployment Nightmare
Getting this code from your development machine to production was an adventure. Not the fun kind.
First, you had to match environments. Your local machine ran PHP 5.3, but the hosting server had PHP 5.2. Your database used utf8mb4 encoding, but production was stuck with utf8. You developed on Windows, but deployment happened on Linux, so file paths broke.
Then came the configuration dance. Apache virtual hosts, mod_rewrite rules, file permissions, database connections. Each hosting provider had different requirements. Shared hosting meant fighting with other sites for resources. VPS hosting meant you were responsible for everything—security patches, backups, monitoring.
Deployment meant FTP uploads. Change a file, upload it. Fix a bug, upload again. No version control integration. No rollback capability. If something broke, you fixed it live in production while users watched error pages.
The Environment Dependencies Hell
Each application was a special snowflake of dependencies. This PHP app needed MySQL 5.5, mod_rewrite enabled, and GD library for image processing. That Java application required Tomcat 7, specific JVM settings, and a particular version of Oracle JDBC drivers.
Installing a second application on the same server often meant dependency conflicts. Different applications needed different versions of the same libraries. One app's configuration could break another's functionality.
Server administrators became experts at managing these conflicts, carefully documenting which packages were installed where and why. Upgrading anything was risky—change the PHP version and three different applications might break in mysterious ways.
When Things Went Wrong
And things went wrong. Often.
Database connections would hang, maxing out connection pools. Memory leaks in application code would slowly consume all available RAM until the server needed a restart. File permission issues would randomly prevent uploads from working. A traffic spike would overwhelm the single server, bringing down the entire site.
Debugging meant SSH-ing into the production server and hunting through log files. No centralized logging. No sophisticated monitoring. Just tail -f and grep, hoping to spot the problem before too many users noticed.
The worst part? Most issues were environment-related. Code that ran perfectly in development would fail in production because of subtle differences in server configuration, installed packages, or system settings.
This was web development for over a decade. It worked, sort of. But it was fragile, complex, and required deep knowledge of server administration alongside application development.
Something had to change. And it did.
Phase 2: The Great Separation - Frontend/Backend Split
The Aha Moment
Someone had a brilliant idea: what if we stopped making the server do everything?
Think about it. Why should the server rebuild the entire page just to update a shopping cart counter? Why reload the whole site when someone clicks "like" on a post? The solution seemed obvious in hindsight. Split the work. Let the browser handle the user interface, and let the server focus on data and business logic. Build the frontend once, then just swap out data as needed.
This wasn't just a technical shift—it changed how development teams worked. Frontend developers could focus on user experience without worrying about server configuration. Backend developers could build APIs without caring about HTML layouts or CSS styling.
Ajax Breaks the Page Reload Cycle
The real breakthrough came with Ajax (Asynchronous JavaScript and XML). Suddenly, browsers could talk to servers without refreshing the entire page. Gmail was one of the first major applications to show what this could look like—reading email felt instant, more like a desktop application than a web page.
// The early Ajax that changed everything
var xhr = new XMLHttpRequest();
xhr.open('POST', '/api/update-cart', true);
xhr.onreadystatechange = function() {
if (xhr.readyState === 4 && xhr.status === 200) {
var response = JSON.parse(xhr.responseText);
document.getElementById('cart-count').innerHTML = response.count;
// No page reload needed!
}
};
xhr.send('item_id=123&quantity=2');This was revolutionary. Users could interact with websites without the jarring white flash of page reloads. Developers could build interfaces that felt responsive and modern.
Ajax also forced a cleaner separation between frontend and backend. Since Ajax requests typically returned JSON instead of HTML, servers naturally evolved toward becoming pure data APIs rather than HTML generators.
Enter the Single Page Application
JavaScript frameworks exploded onto the scene, building on Ajax's foundation. AngularJS promised to turn browsers into application platforms. React introduced a component-based approach that made complex interfaces manageable. Vue offered a gentler learning curve for developers migrating from server-side templates.
Suddenly, websites started feeling like real applications. No more page refreshes. Smooth transitions. Instant feedback. The loading spinner became the new progress bar.
// Frontend code that felt like magic after years of PHP templates
function updateCartCount() {
fetch('/api/cart/count') // The modern evolution of Ajax
.then(response => response.json())
.then(data => {
document.getElementById('cart-count').textContent = data.count;
});
}Static Sites Make a Comeback
Then something interesting happened. Developers realized that many parts of websites didn't need to be dynamic at all. Blog posts, marketing pages, documentation—this content changed occasionally, not with every request.
Why generate the same HTML over and over when you could build it once and serve it from a CDN?
Static site generators like Jekyll and Hugo gained popularity. Write content in Markdown, run a build process, get optimized HTML files. Deploy those files to a CDN and watch your site load instantly from anywhere in the world.
JAMstack Changes the Game
The JAMstack methodology took this further. JavaScript for dynamic functionality, APIs for server-side operations, and Markup pre-built at deploy time.
The workflow became elegant:
- Write your site using a static site generator
- Deploy the static files to a global CDN
- Use JavaScript to call APIs when you need dynamic data
- Trigger a rebuild when content changes
This approach solved multiple problems at once. Sites loaded incredibly fast because static files served from CDNs are nearly instant. Security improved because there was less attack surface—no database connections or server-side code execution for most requests. Scaling became automatic since CDNs handle traffic spikes effortlessly.
Development Teams Split Too
The architectural separation led to team separation. Frontend teams could iterate on user experience without waiting for backend changes. Backend teams could refactor APIs without breaking the UI.
But this also created new coordination challenges. API contracts became critical. Frontend teams needed mock data for development. Backend teams had to think carefully about API design since changes could break multiple client applications.
Version compatibility became a constant concern. The frontend expected specific API responses, but the backend evolved independently. Teams learned the hard way about versioning APIs and maintaining backward compatibility.
New Problems Emerged
Frontend/backend separation solved many issues but created others.
Build processes became complex. Modern frontend applications required bundlers, transpilers, minifiers, and dozens of dependencies. A simple "hello world" React app might pull in hundreds of npm packages.
{
"devDependencies": {
"webpack": "^5.0.0",
"babel-core": "^6.26.3",
"babel-preset-react": "^6.24.1",
"css-loader": "^6.0.0",
"sass-loader": "^12.0.0",
"eslint": "^8.0.0"
// ... and 47 more packages
}
}CORS became the new Apache configuration nightmare. Getting the browser to talk to APIs hosted on different domains required careful header configuration. Development environments needed proxy setups to avoid CORS issues locally.
SEO suffered initially. Search engines struggled with JavaScript-heavy sites that rendered content client-side. Server-side rendering solutions emerged to fix this, bringing back some of the complexity that SPAs were supposed to eliminate.
The Sweet Spot
Despite the new challenges, frontend/backend separation was a massive improvement. Development velocity increased. User experiences got better. Teams could work more independently.
The combination of static site generation, CDN hosting, and API-driven backends proved especially powerful. Sites loaded fast, handled traffic spikes gracefully, and were relatively simple to maintain.
Phase 3: Serverless + Edge - The Performance Revolution
The Uncomfortable Question
As teams become increasingly proficient in service deployment, certain companies begin posing an unsettling question: Why should we manage infrastructure at all?
Think about it. Developers wanted to write code that responds to HTTP requests. But they were spending time mastering frontend frameworks, designing backend APIs, coordinating database schemas, managing authentication flows, and keeping frontend and backend changes synchronized. When did "building a web app" become synonymous with "being an expert across the entire technology stack"?
The serverless movement said: forget all that. Just write functions. We'll handle the rest.
// The entire "server" for a simple API
export default function handler(request) {
const { name } = request.query;
return new Response(`Hello, ${name}!`);
}Deploy that function, and it automatically:
- Runs on servers you'll never see
- Scales from zero to thousands of concurrent executions
- Handles SSL certificates and domain routing
- Provides logging and monitoring
- Charges you only for actual usage
No Dockerfiles. No Kubernetes yaml. No server maintenance. Just functions.
Functions Everywhere
The concept caught on fast. AWS Lambda led the charge, followed by Google Cloud Functions, Azure Functions, and eventually platforms like Vercel, Netlify and EdgeOne that made serverless deployment brain-dead simple.
Suddenly, that complex microservices architecture could be simplified dramatically:
// User service - just a function
export async function getUser(request) {
const { id } = request.params;
const user = await db.users.findById(id);
return Response.json(user);
}
// Order service - another function
export async function createOrder(request) {
const orderData = await request.json();
const order = await db.orders.create(orderData);
return Response.json(order);
}
// Payment service - you get the idea
export async function processPayment(request) {
const { amount, token } = await request.json();
const result = await stripe.charges.create({ amount, source: token });
return Response.json(result);
}Each function deployed independently. No containers to build. No orchestration to configure. Just functions that responded to HTTP requests.
Edge Computing Changes the Game
But serverless platforms took things further. Instead of running functions in a few data centers, they deployed them to edge locations worldwide. Your function might run in Virginia for users on the East Coast, London for European users, and Tokyo for Asian users.
This wasn't just about redundancy—it was about physics. Light travels fast, but not infinitely fast. A request from Sydney to a server in Virginia takes hundreds of milliseconds just for the round trip. Move that function to Sydney, and suddenly it responds in under 50ms.
Cloudflare Workers, Vercel Edge Functions, EdgeOne Pages and similar platforms deployed code to hundreds of edge locations automatically. Users in São Paulo got responses from São Paulo. Users in Mumbai got responses from Mumbai. Global performance became a deployment default, not an expensive add-on.
The New Deployment Reality
The deployment process became almost boring:
git push origin mainThat's it. The platform detected the code change, built the functions, and deployed them globally. No build servers to maintain. No deployment scripts to debug. No rollback procedures to memorize.
The developer experience became magical. Push code, get a live URL immediately. Share feature branches with teammates before merging. A/B test different implementations by deploying to different URLs.
The Pricing Revolution
Speaking of cost, serverless flipped the economics of web hosting. Instead of paying for servers whether they were busy or idle, you paid only for actual usage.
- Traditional hosting: $50/month for a VPS, whether it serves 10 requests or 10 million.
- Serverless: $0.00 for zero requests, scales up based on actual traffic.
This made experimentation cheap. Launch 10 side projects, pay only for the ones that get traction. Run development and staging environments that cost pennies because they're barely used.
The Dark Side of Serverless
But serverless is not perfect. Cold starts have become the new performance enemy. When a function hasn't run recently, the platform needs time to initialize the runtime environment. For some platforms, this means hundreds of milliseconds of delay—terrible for user experience.
Debugging becomes strange. When your functions run in hundreds of edge locations, where exactly did the error occur? Logs are scattered, and error tracking becomes more complex. Local development requires simulating edge environments.
Serverless functions come with constraints. Most platforms limit execution time to seconds or minutes. Memory is restricted, and some operations that work well on traditional servers hit platform limits.
Large file processing, long-running computations, and stateful applications don't fit well in the serverless model. Database connections become tricky. Functions scale to thousands of concurrent executions, but databases have connection limits. Connection pooling services become a new category of infrastructure.
However, these challenges are driving a new generation of innovation.
Cold start problems have pushed technologies like Firecracker micro-VMs, reducing startup times to tens of milliseconds. WebAssembly is becoming a new runtime choice, offering near-instant startup speeds. Mainstream cloud providers are beginning to offer "warming" mechanisms and smart prediction, gradually making cold starts a thing of the past.
Debugging tools are evolving rapidly. Distributed tracing, intelligent log aggregation, and AI-assisted error diagnosis make complex environments manageable. Observability for edge computing is becoming a new technology track.
More importantly, Serverless 2.0 is taking shape—supporting long-running tasks, stateful computation, and more flexible resource configuration. Databases are also adapting to this new world; serverless databases and intelligent connection pools ensure the data layer is no longer a bottleneck.
We're standing at an inflection point: today's pain points are tomorrow's innovation opportunities. Serverless isn't the end point, but a necessary path toward a future where we truly "don't need to worry about infrastructure."
The Edge Native Future
Despite the limitations, serverless and edge computing represented a fundamental shift. Platforms started offering more than just function execution:
- Edge databases that replicated data globally
- Key-value stores built into the edge runtime
- File storage that automatically distributed assets worldwide
- Analytics and monitoring built into the platform
The vision was becoming clear: applications that ran entirely at the edge, with data and compute distributed globally by default. No servers to manage, no infrastructure to configure, just code that automatically optimized for performance and scale.
This wasn't just about convenience anymore. It was about building applications that were fundamentally faster and more reliable than anything possible with traditional server architectures.
Conclusion
Looking Back at the Journey
It's wild to think about how far we've come.
We started with developers manually configuring Apache virtual hosts, fighting PHP version conflicts, and FTPing files to production servers. Every deployment was a gamble. Every environment was a special snowflake. Scaling meant buying bigger servers and crossing your fingers.
Then came the great separation. Ajax freed us from full page reloads. SPAs made websites feel like real applications. JAMstack showed that pre-built static sites could be blazingly fast. Teams could finally work independently on frontend and backend. But we traded monolithic complexity for coordination complexity.
Serverless and edge computing abstracted away the infrastructure entirely. Functions deployed globally in seconds. Scaling became automatic. Pay-per-use pricing made experimentation cheap. Edge locations brought compute closer to users. But cold starts, vendor lock-in, and platform limitations created new constraints.
The Pattern Emerges
Each phase followed the same pattern:
- Solve the biggest pain point of the previous era
- Enable new possibilities that weren't feasible before
- Introduce new types of complexity and trade-offs
- Set the stage for the next evolutionary leap
Server-side rendering solved static content limitations but created deployment complexity. Frontend/backend separation solved deployment complexity by splitting concerns, but created coordination overhead between teams. Full-stack development solved coordination overhead by unifying development workflows, but created steep learning curves requiring broad technical expertise. Serverless solved the infrastructure management burden that made full-stack development overwhelming, but introduced platform constraints and vendor dependencies.
The progression isn't random. Each phase built directly on the previous one's strengths while addressing its weaknesses. We didn't abandon good ideas—we refined them. Static sites didn't disappear; they evolved into JAMstack. APIs didn't go away; they became serverless functions. Containers didn't become obsolete; they became the foundation for serverless platforms.
Where We Stand Today
Modern web deployment is incredibly powerful compared to where we started. Developers can deploy applications globally in minutes, not days. Sites automatically scale from zero to millions of users. Performance optimizations that required teams of experts are now built into platforms.
But challenges remain. Teams still juggle multiple platforms for different needs. Global performance optimization requires platform-specific knowledge. Enterprise compliance adds complexity to simple workflows. The ideal deployment experience continues to evolve.
EdgeOne Pages: Continuing the Evolution
EdgeOne Pages represents the next step in this evolutionary path. Built on Tencent EdgeOne's global infrastructure, it's designed as a frontend development and deployment platform for modern web applications.
The platform addresses several key issues that still persist in current solutions:
- Global Distribution: EdgeOne Pages leverages Tencent Cloud's worldwide content delivery network to cache static resources at edge nodes closest to users. This approach builds global performance optimization directly into the deployment process rather than requiring separate CDN configuration.
- Streamlined Deployment: The platform integrates with code repositories like GitHub to automatically build and deploy websites on every code commit. This continues the trend toward automated deployment workflows while reducing the time from development to production.
- Serverless Functions: Through Functions, developers can write JavaScript code that executes at edge locations near users, enabling dynamic functionality without traditional server management. The platform also provides centralized Node.js service capabilities to meet developers complex requirements.
- Modern Framework Support: EdgeOne Pages works seamlessly with popular full-stack frameworks like Next.js, enabling rapid deployment of full-stack web applications.
These capabilities continue the industry trend toward abstracting infrastructure complexity while enabling global performance and modern development workflows.
The Evolution Continues
Web deployment will keep evolving. New challenges will emerge. Better solutions will be invented. That's the nature of technology.
The journey from manually configuring Apache to edge-native deployment platforms shows consistent progress toward simplifying the deployment experience while enabling more sophisticated applications. Each evolutionary phase built on previous innovations while solving the limitations that emerged.
EdgeOne Pages represents one approach to continuing this evolution, focusing on global performance, simplified deployment workflows, and edge-native architecture. As the industry moves forward, platforms will continue refining the balance between developer experience, performance, and operational complexity.